40 variational autoencoder for deep learning of images labels and captions
The NLP Index - Quantum Stat 25.09.2022 · The key components of DeID-VC include a Variational Autoencoder (VAE) based Pseudo Speaker Generator (PSG) and a voice conversion Autoencoder (AE) under zero-shot settings. With the help of PSG, DeID-VC can assign unique pseudo speakers at speaker level or even at utterance level. Also, two novel learning objectives are added to bridge the gap … A Semi-supervised Learning Based on Variational Autoencoder for Visual ... This paper presents a novel semi-supervised learning method based on Variational Autoencoder (VAE) for visual-based robot localization, which does not rely on the prior location and feature points. Because our method does not need prior knowledge, it also can be used as a correction of dead reckoning.
Variational Autoencoder for Deep Learning of Images, Labels and Captions Variational Autoencoder for Deep Learning of Images, Labels and Captions Yunchen Pu, Zhe Gan, Ricardo Henao, Xin Yuan, Chunyuan Li, Andrew Stevens, Lawrence Carin A novel variational autoencoder is developed to model images, as well as associated labels or captions.
Variational autoencoder for deep learning of images labels and captions
PDF Variational Autoencoder for Deep Learning of Images, Labels and Captions Title: Variational Autoencoder for Deep Learning of Images, Labels and Captions Author: Yunchen Pu , Zhe Gan , Ricardo Henao , Xin Yuan , Chunyuan Li , Andrew Stevens and Lawrence Carin PDF Variational Autoencoder for Deep Learning of Images, Labels and Captions 2 Variational Autoencoder Image Model 2.1 Image Decoder: Deep Deconvolutional Generative Model Consider Nimages fX(n)gN n=1 , with X (n)2RN x y c; N xand N yrepresent the number of pixels in each spatial dimension, and N cdenotes the number of color bands in the image (N c= 1 for gray-scale images and N c= 3 for RGB images). Accepted papers | EMNLP 2021 Classification of hierarchical text using geometric deep learning: the case of clinical trials corpus. Sohrab Ferdowsi, Nikolay Borissov, Julien Knafou, Poorya Amini and Douglas Teodoro . XTREME-R: Towards More Challenging and Nuanced Multilingual Evaluation. Sebastian Ruder, Noah Constant, Jan Botha, Aditya Siddhant, Orhan Firat, Jinlan Fu, Pengfei Liu, Junjie Hu, Dan …
Variational autoencoder for deep learning of images labels and captions. A robust variational autoencoder using beta divergence Abstract The presence of outliers can severely degrade learned representations and performance of deep learning methods and hence disproportionately affect the training process, leading to incorrec... Image Captioning: An Eye for Blind | by Akash Rawat - Medium The objective of this study is to design a variational autoencoder to model images as well as associated labels or captions. In this model, the dataset used was extracted from the Flickr8k dataset… Variational Autoencoder for Deep Learning of Images, Labels and Captions +4 authors L. Carin Published in NIPS 28 September 2016 Computer Science A novel variational autoencoder is developed to model images, as well as associated labels or captions. [ ... ] The latent code is also linked to generative models for labels (Bayesian support vector machine) or captions (recurrent neural network). Variational autoencoder meaning A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the latent DGDN ...
Design of Variational Autoencoder for Generation of Odia Handwritten ... Autoencoders are the basic building components of generative models. In this work, we have designed a variational autoencoder to generate a large number of data to support the generative adversarial network model. The encoder, as well as the decoder of the proposed model, is designed using convolutional layers. Deep Generative Models for Image Representation Learning - Duke University The first part developed a deep generative model joint analysis of images and associated labels or captions. The model is efficiently learned using variational autoencoder. A multilayered (deep) convolutional dictionary representation is employed as a decoder of the Variational autoencoder meaning - datensicherheit24h.de A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the latent DGDN ... Variational Autoencoders as Generative Models with Keras In the past tutorial on Autoencoders in Keras and Deep Learning, we trained a vanilla autoencoder and learned the latent features for the MNIST handwritten digit images. When we plotted these embeddings in the latent space with the corresponding labels, we found the learned embeddings of the same classes coming out quite random sometimes and ...
Variational autoencoder - urxxk.longrangesportgruppe.de A variational autoencoder (VAE) provides a probabilistic manner for describing an observation in latent space. Thus, rather than building an encoder which outputs a single value. beachie creek fire ace hardware pocket knives nefyn holiday homes for sale Tech transformational leadership style traits ocean pines golf clubhouse hisoka x pregnant ... Variational Autoencoder for Deep Learning of Images, Labels and Captions The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the latent DGDN features/code. Variational autoencoder Variational Autoencoder for Deep Learning of Images, Labels and Captions Yunchen Puy, Zhe Gan , Ricardo Henao , Xin Yuanz, Chunyuan Liy, Andrew Stevens and Lawrence Cariny yDepartment of Electrical and Computer Engineering, Duke University {yp42, zg27, r.henao, cl319, ajs104, lcarin}@duke.edu zNokia Bell Labs, Murray Hill [email protected] Variational autoencoder Beta variational autoencoder. pedram1 (pedram) June 30, 2020, 1:38am #1.Hi All. has anyone worked with "Beta- variational autoencoder"? ...Here's an old implementation of mine ( pytorch v 1.0 I guess or maybe 0.4). this is also known as disentagled variational auto encoder.A variational autoencoder (VAE) is a generative model, meaning that we would like it to be able to generate plausible ...
Time series Anomaly Detection using a Variational Autoencoder ...
Deep clustering with convolutional autoencoders Deep Clustering with Variational Autoencoder Kart-Leong Lim and ... Matlab Convolutional Autoencoder. Deep learning can also be used to improve the detection of abnormalities in a vehicle's sensor signals for the prediction of system faults or failures. Existing diagnostics of on-board systems are typically triggered from a limited sensor domain such as the emissions …
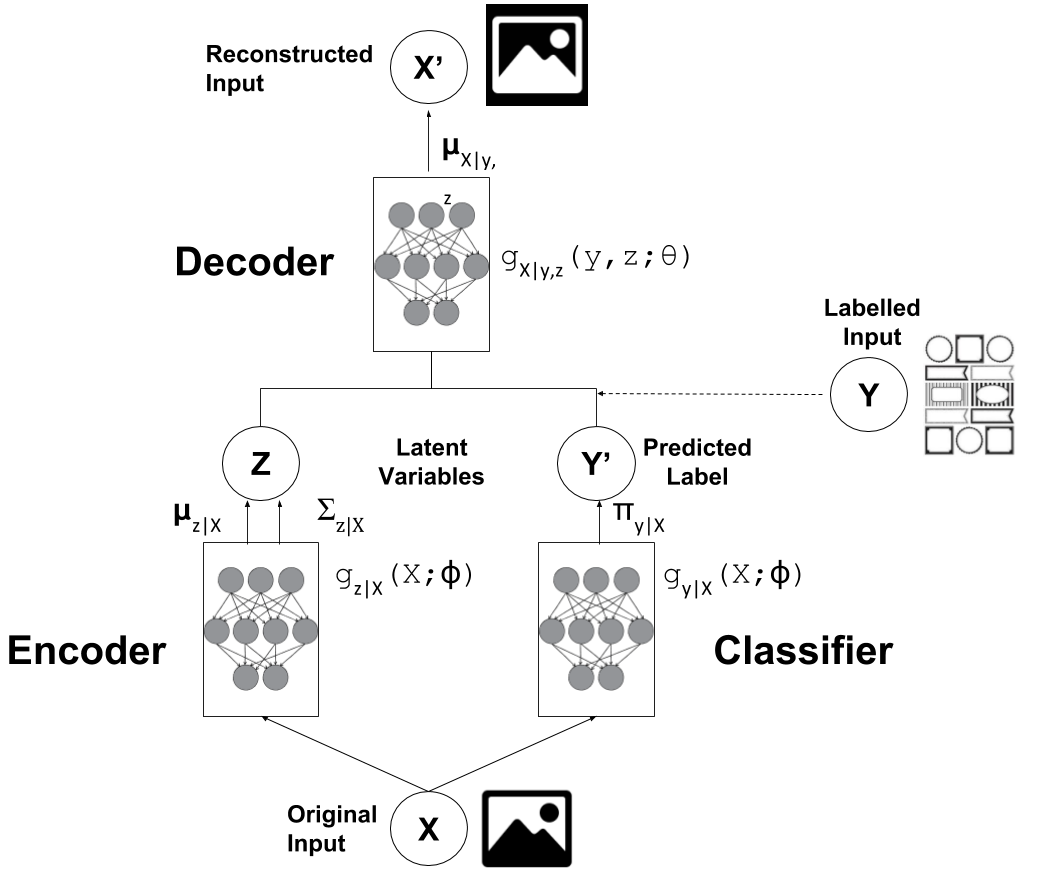
Semi-supervised Learning with Variational Autoencoders ...
Deep Learning for Geophysics: Current and Future Trends An autoencoder learns to reconstruct the inputs with useful representations with an encoder and a decoder ... where seismic images are inputs and areas with labels as different attributes are output. Therefore, DNNs for image classification can be directly applied in seismic attribute analysis (Das et al., 2019; Feng, Mejer Hansen, et al., 2020; You et al., 2020). If the attributes …
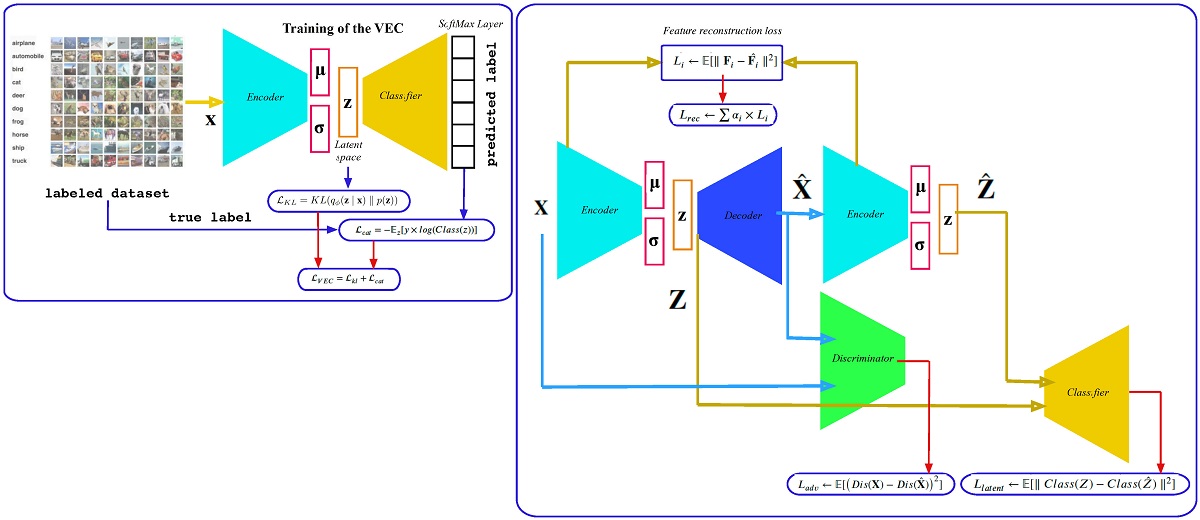
Semi-supervised Adversarial Variational Autoencoder[v1 ...
[PDF] Stein Variational Autoencoder | Semantic Scholar A new method for learning variational autoencoders is developed, based on an application of Stein's operator, which represents the encoder as a deep nonlinear function through which samples from a simple distribution are fed. A new method for learning variational autoencoders is developed, based on an application of Stein's operator. The framework represents the encoder as a deep nonlinear ...

Train Variational Autoencoder (VAE) to Generate Images ...
Chunyuan Li - Google Scholar Variational Autoencoder for Deep Learning of Images, Labels and Captions. Y Pu, Z Gan, R Henao, X Yuan, C Li, A Stevens, L Carin ... Joint Embedding of Words and Labels for Text Classification. G Wang, C Li, W Wang, Y Zhang, D Shen, X Zhang, R Henao, L Carin ... Cyclical Stochastic Gradient MCMC for Bayesian Deep Learning. R Zhang, C Li, J ...
![PDF] Variational Autoencoder for Deep Learning of Images ...](https://d3i71xaburhd42.cloudfront.net/f4c5d13a8e9e80edcd4f69f0eab0b4434364c6dd/7-Figure1-1.png)
PDF] Variational Autoencoder for Deep Learning of Images ...
Variational Autoencoder for Deep Learning of Images, Labels and Captions Pu et al. [63] designed a variational autoencoder for deep learning applied to classifying images, labels, and captions. A CNN was used as the encoder to distribute the latent features to be...
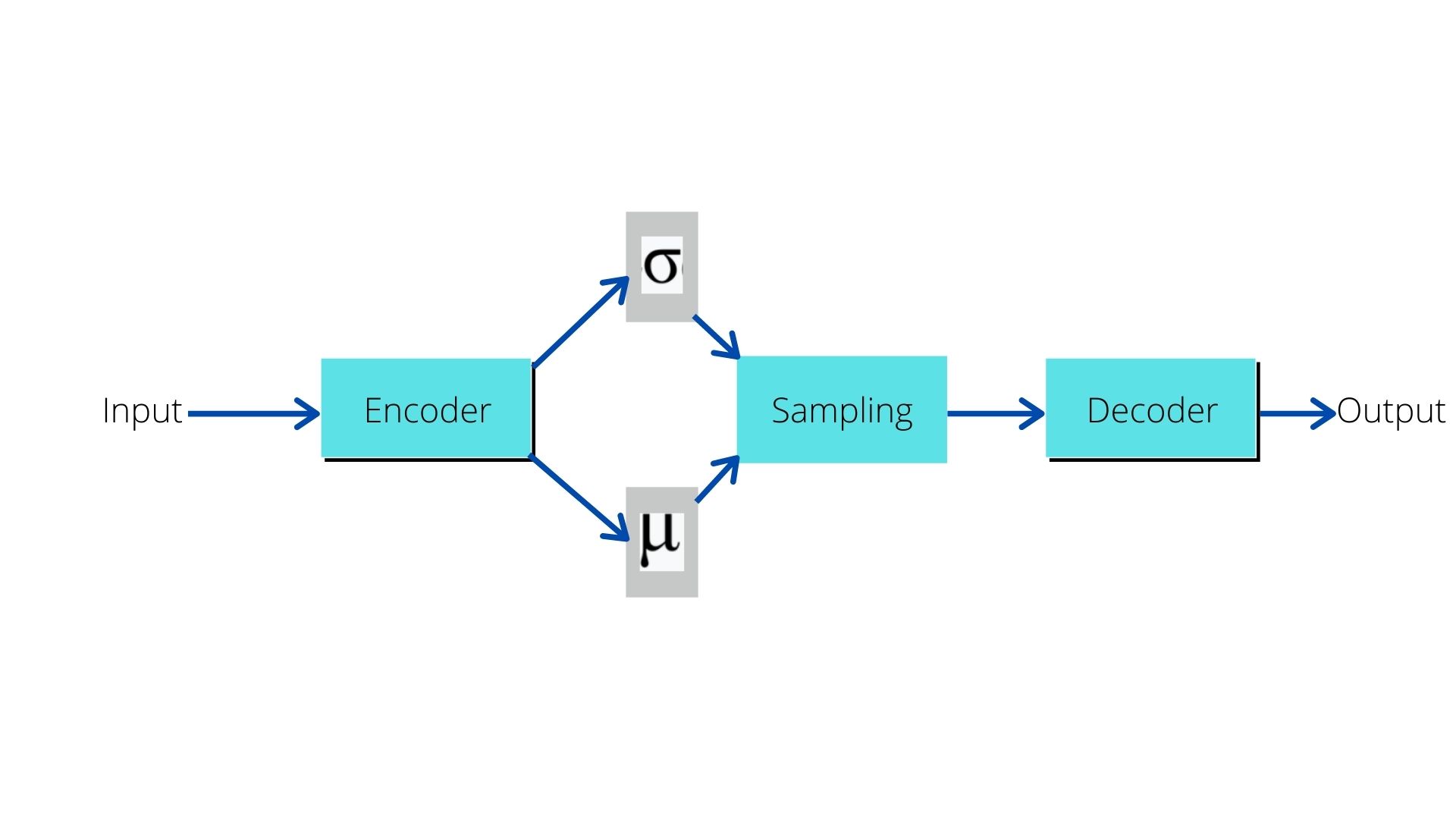
Convolutional Variational Autoencoder in PyTorch on MNIST ...
ISCA Archive Deep Learning Based Assessment of Synthetic Speech Naturalness ... Complex-Valued Variational Autoencoder: A Novel Deep Generative Model for Direct Representation of Complex Spectra Toru Nakashika Attentron: Few-Shot Text-to-Speech Utilizing Attention-Based Variable-Length Embedding Seungwoo Choi, Seungju Han, Dongyoung Kim, Sungjoo Ha Reformer-TTS: …
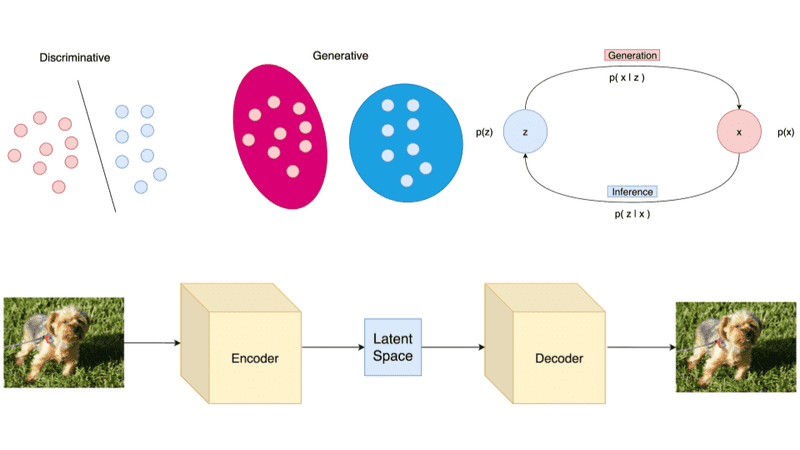
The theory behind Latent Variable Models: formulating a ...
GitHub - shivakanthsujit/VAE-PyTorch: Variational Autoencoders trained ... Variational Autoencoder for Deep Learning of Images, Labels and Captions Types of VAEs in this project Vanilla VAE Deep Convolutional VAE ( DCVAE ) The Vanilla VAE was trained on the FashionMNIST dataset while the DCVAE was trained on the Street View House Numbers ( SVHN) dataset. To run this project pip install -r requirements.txt python main.py
Variational Autoencoder for Semi-Supervised Text Classification
Robust Variational Autoencoder | DeepAI Variational autoencoders (VAEs) extract a lower dimensional encoded feature representation from which we can generate new data samples. Robustness of autoencoders to outliers is critical for generating a reliable representation of particular data types in the encoded space when using corrupted training data.
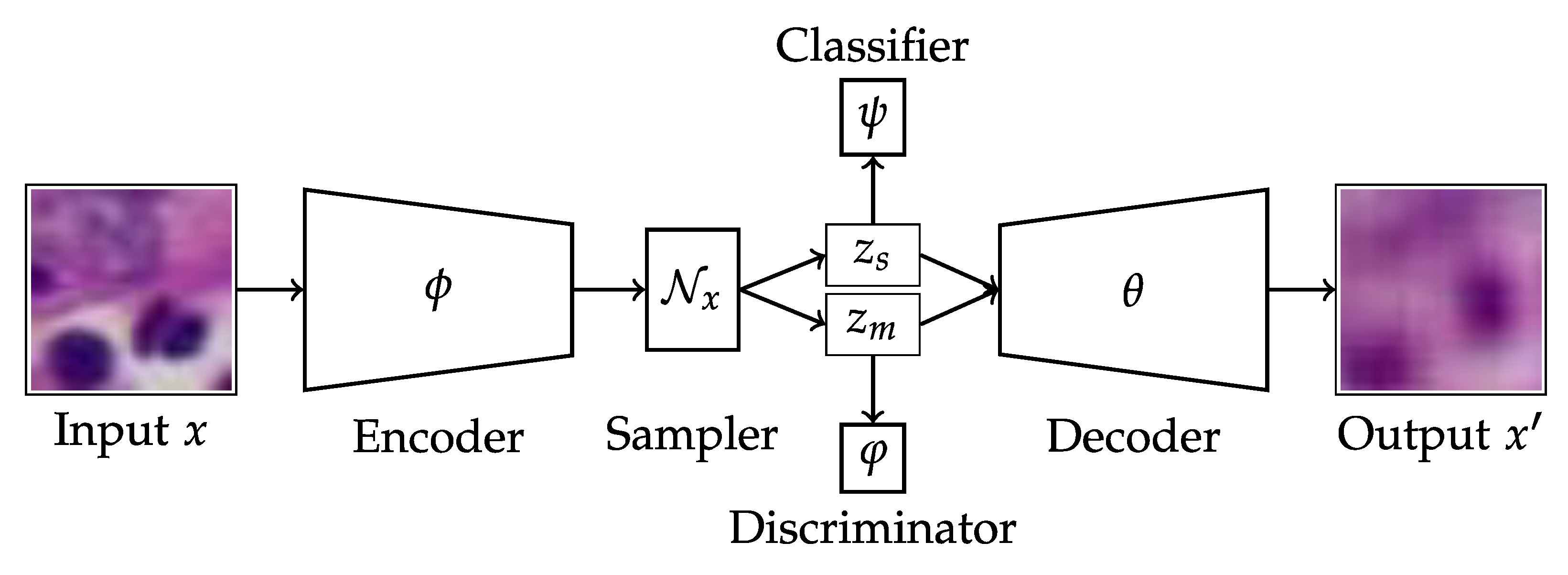
Applied Sciences | Free Full-Text | Disentangled Autoencoder ...
Variational Autoencoder for Deep Learning of Images, Labels and Captions Since the framework is capable of modeling the image in the presence/absence of associated labels/captions, a new semi-supervised setting is manifested for CNN learning with images; the framework even allows unsupervised CNN learning, based on images alone. PDF Abstract NeurIPS 2016 PDF NeurIPS 2016 Abstract Code Edit No code implementations yet.

Variational autoencoder as a method of data augmentation ...
Reviews: Variational Autoencoder for Deep Learning of Images, Labels ... Variational autoencoder has been hotly discussed in CV domains e.g. image classification and image generation. However, the method proposed in this paper does not provide a new perspective for these domains. Although the authors did a lot work on experiments, it's incomplete. The evidences are weak and may lead to a incorrect conclusion.
Variational Autoencoder for Deep Learning of Images, Labels ...
Variational Autoencoder for Deep Learning of Images, Labels and ... 摘要: In this paper, we propose a Recurrent Highway Network with Language CNN for image caption generation. Our network consists of three sub-networks: the deep Convolutional Neural Network for image representation, the Convolutional Neural Network for language modeling, and the Multimodal Recurrent Highway Network for sequence prediction.
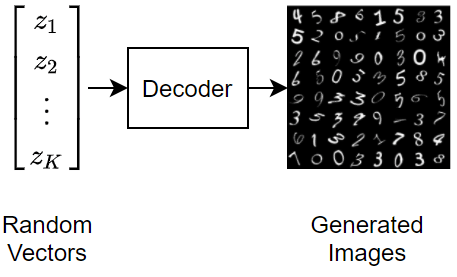
Train Variational Autoencoder (VAE) to Generate Images ...
Deep Learning-Based Autoencoder for Data-Driven Modeling of an RF ... A deep convolutional neural network (decoder) is used to build a 2D distribution from a small feature space learned by another neural network (encoder). We demonstrate that the autoencoder model trained on experimental data can make fast and very high-quality predictions of megapixel images for the longitudinal phase-space measurement.
Gaussian Mixture Variational Autoencoder with Contrastive ...
Variational Autoencoder for Deep Learning of Images, Labels and Captions A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the latent DGDN ...
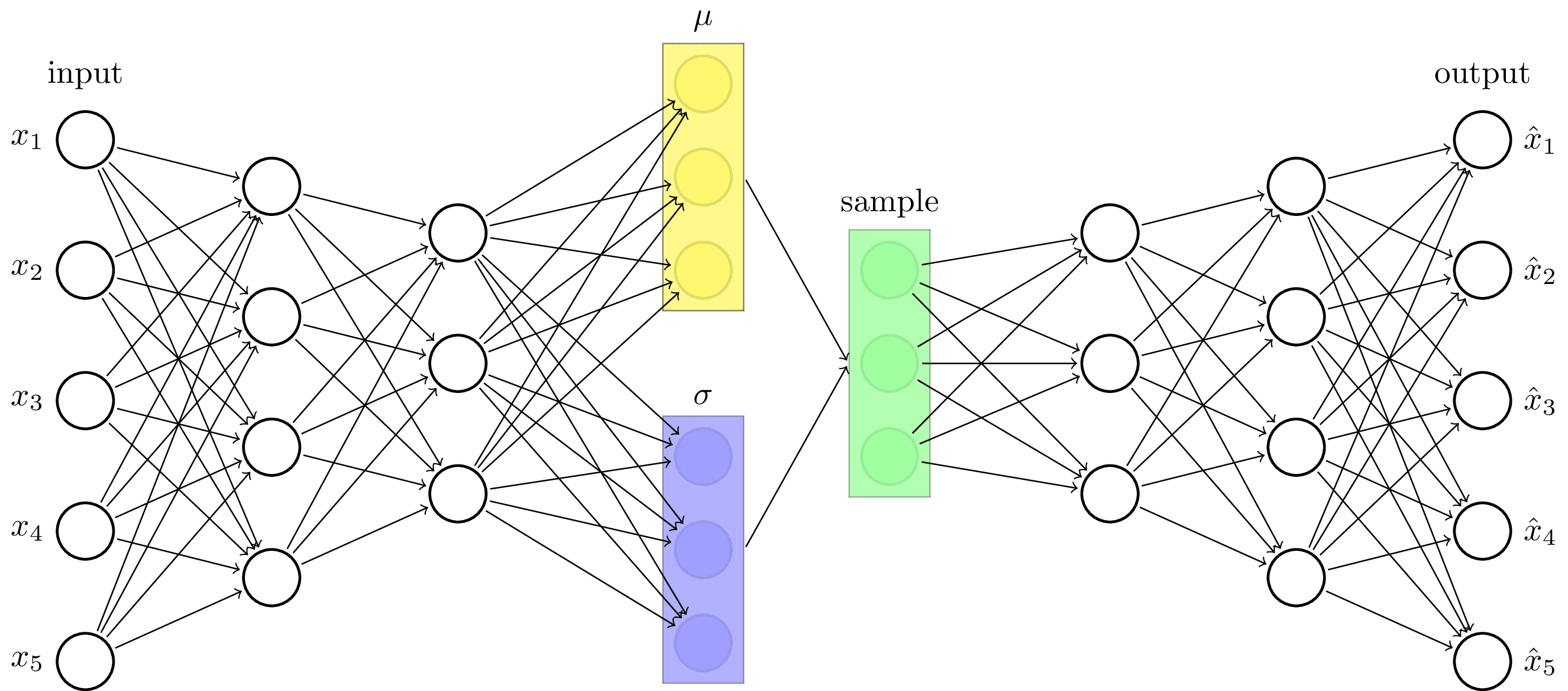
Variational Auto Encoder Architecture – TikZ.net
Variational autoencoder for deep learning of images, labels and ... Variational autoencoder for deep learning of images, labels and captions Pages 2360-2368 ABSTRACT References Comments ABSTRACT A novel variational autoencoder is developed to model images, as well as associated labels or captions.
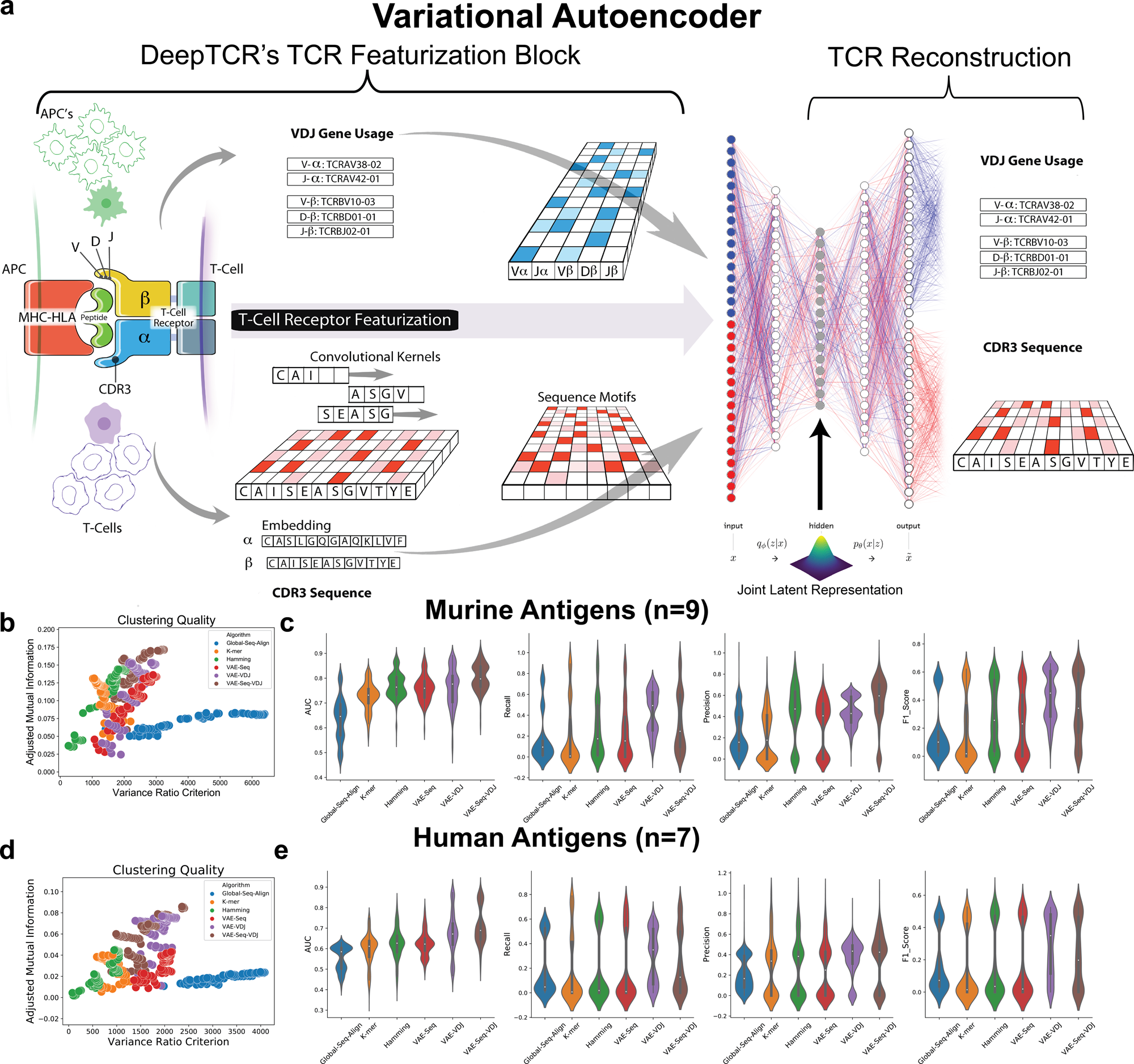
DeepTCR is a deep learning framework for revealing sequence ...
PDF Variational Autoencoder for Deep Learning of Images, Labels and Captions on image-caption modeling, in which we demonstrate the advantages of jointly learning the image features and caption model (we also present semi-supervised experiments for image captioning). 2 Variational Autoencoder Image Model 2.1 Image Decoder: Deep Deconvolutional Generative Model Consider N images fX (n )g N n =1, with X (n ) 2 R N x y N c; N
![Autoencoders in Deep Learning: Tutorial & Use Cases [2022]](https://assets-global.website-files.com/5d7b77b063a9066d83e1209c/627d121bd4fd200d73814c11_60bcd0b7b750bae1a953d61d_autoencoder.png)
Autoencoders in Deep Learning: Tutorial & Use Cases [2022]
Accepted papers | EMNLP 2021 Classification of hierarchical text using geometric deep learning: the case of clinical trials corpus. Sohrab Ferdowsi, Nikolay Borissov, Julien Knafou, Poorya Amini and Douglas Teodoro . XTREME-R: Towards More Challenging and Nuanced Multilingual Evaluation. Sebastian Ruder, Noah Constant, Jan Botha, Aditya Siddhant, Orhan Firat, Jinlan Fu, Pengfei Liu, Junjie Hu, Dan …
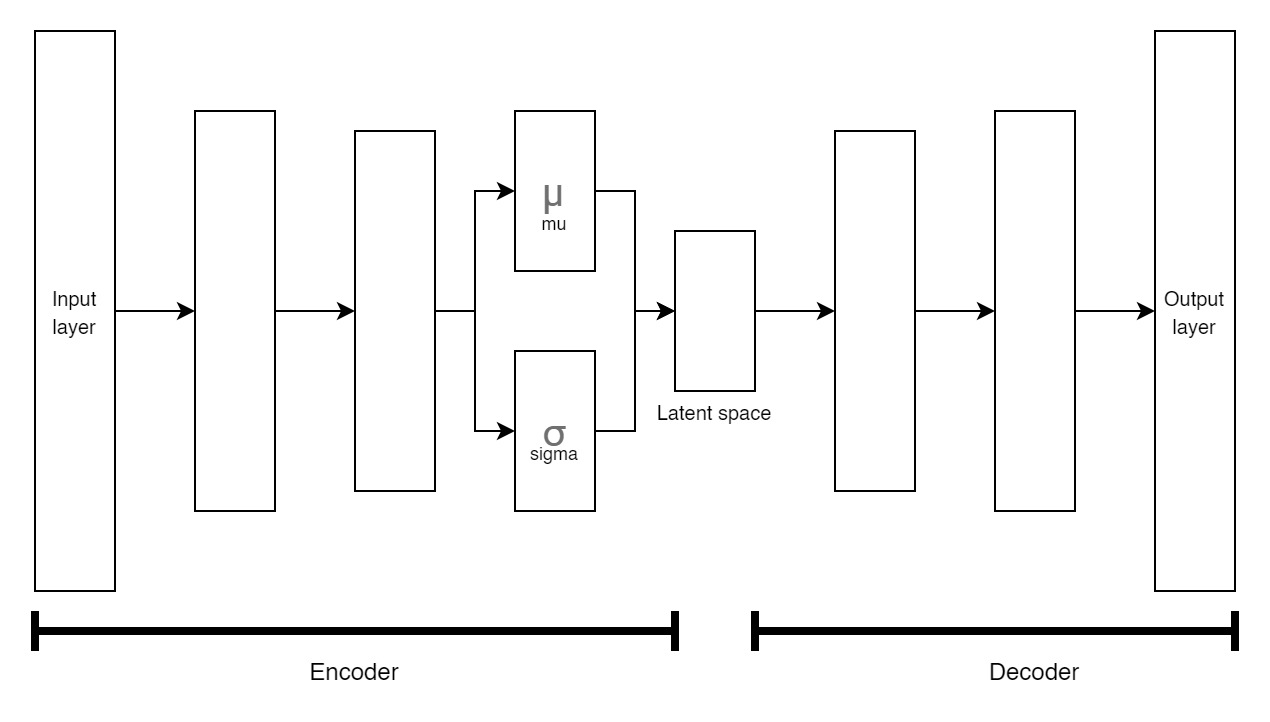
Using Variational Autoencoder (VAE) to Generate New Images ...
PDF Variational Autoencoder for Deep Learning of Images, Labels and Captions 2 Variational Autoencoder Image Model 2.1 Image Decoder: Deep Deconvolutional Generative Model Consider Nimages fX(n)gN n=1 , with X (n)2RN x y c; N xand N yrepresent the number of pixels in each spatial dimension, and N cdenotes the number of color bands in the image (N c= 1 for gray-scale images and N c= 3 for RGB images).

Introduction to Variational Autoencoders Using Keras
PDF Variational Autoencoder for Deep Learning of Images, Labels and Captions Title: Variational Autoencoder for Deep Learning of Images, Labels and Captions Author: Yunchen Pu , Zhe Gan , Ricardo Henao , Xin Yuan , Chunyuan Li , Andrew Stevens and Lawrence Carin
![PDF] Fully Convolutional Variational Autoencoder For Feature ...](https://d3i71xaburhd42.cloudfront.net/a03d73acee093f2c1cf2bb22eecfe1424238ed8b/3-Figure3-1.png)
PDF] Fully Convolutional Variational Autoencoder For Feature ...

14. Variational Autoencoder — deep learning for molecules ...

Convolutional variational autoencoder architecture. The deep ...

Representation learning of resting state fMRI with ...

Deep learning feature extraction from CT images through an ...
Vision Language models: towards multi-modal deep learning ...
Unsupervised deep learning identifies semantic ...

VQ-VAE-2 Explained | Papers With Code
Variational Autoencoder for Image-Based Augmentation of Eye ...
Partitioning variability in animal behavioral videos using ...

Comparison of adversarial and variational autoencoder on ...

VAE: giving your Autoencoder the power of imagination
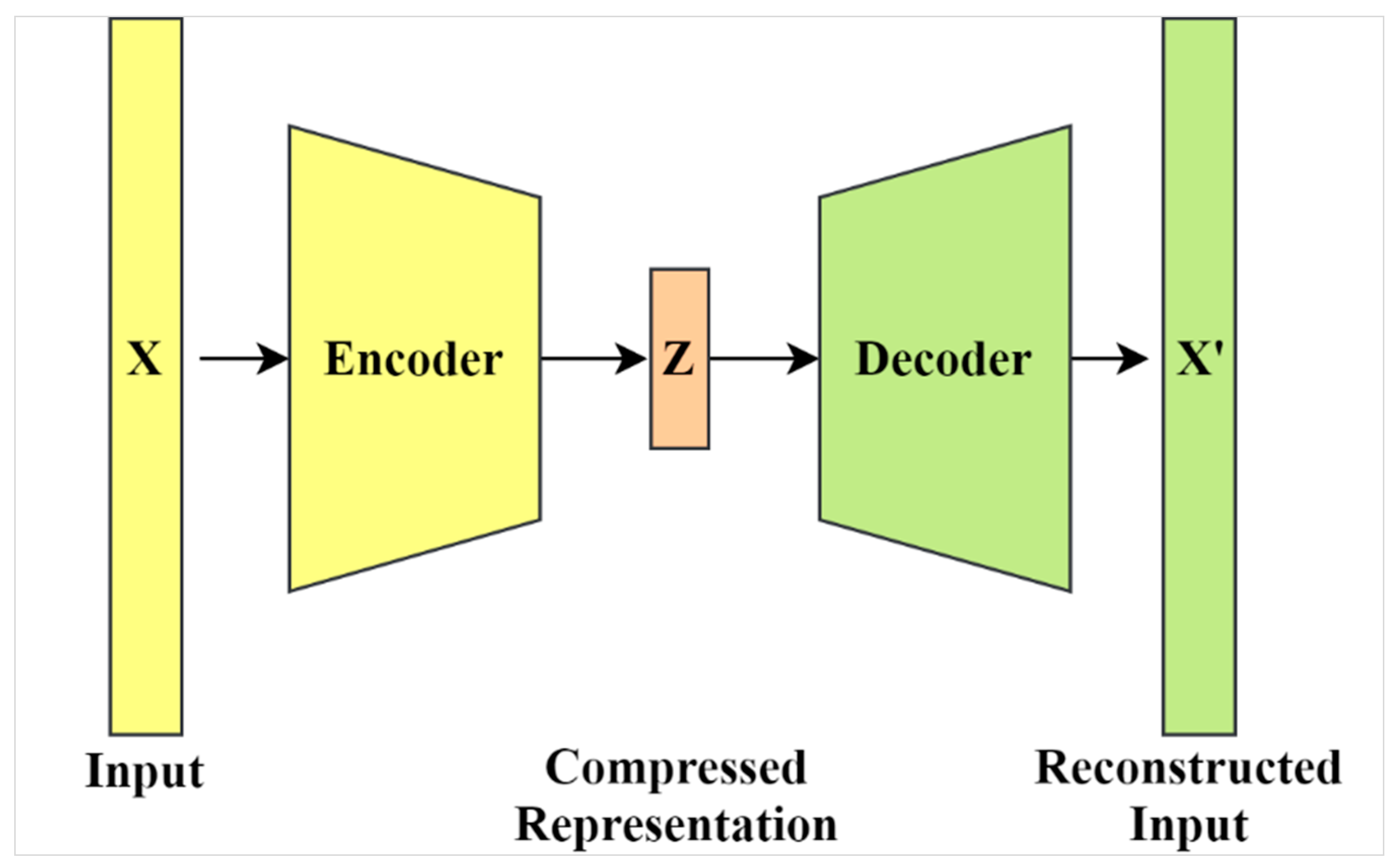
J. Imaging | Free Full-Text | Variational Autoencoder for ...

Guided Variational Autoencoder for Disentanglement Learning ...
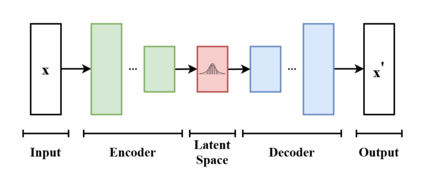
Variational autoencoder - Wikipedia

Variational Autoencoder for Deep Learning of Images, Labels ...
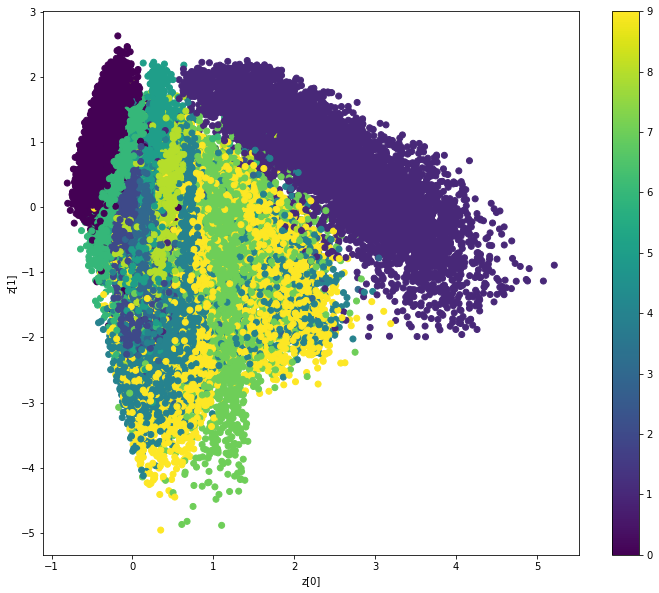
Variational AutoEncoder
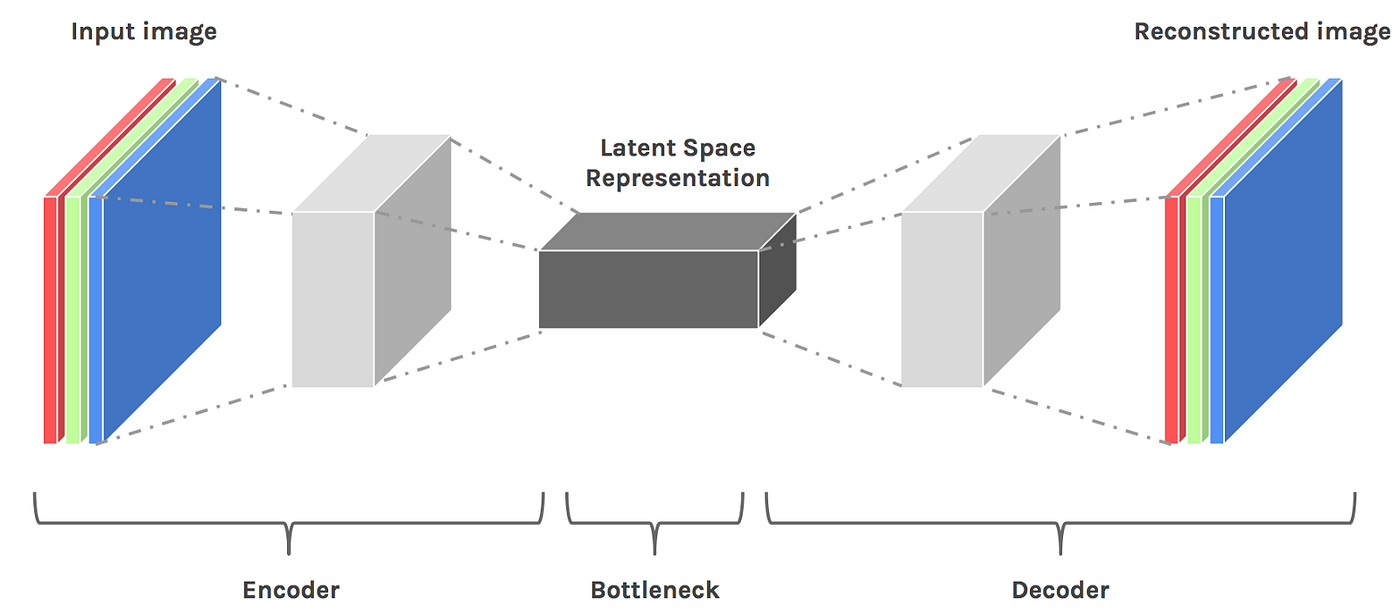
Image Classification Using the Variational Autoencoder | by ...

Face Image Generation using Convolutional Variational ...

Variational AutoEncoders and Image Generation with Keras ...
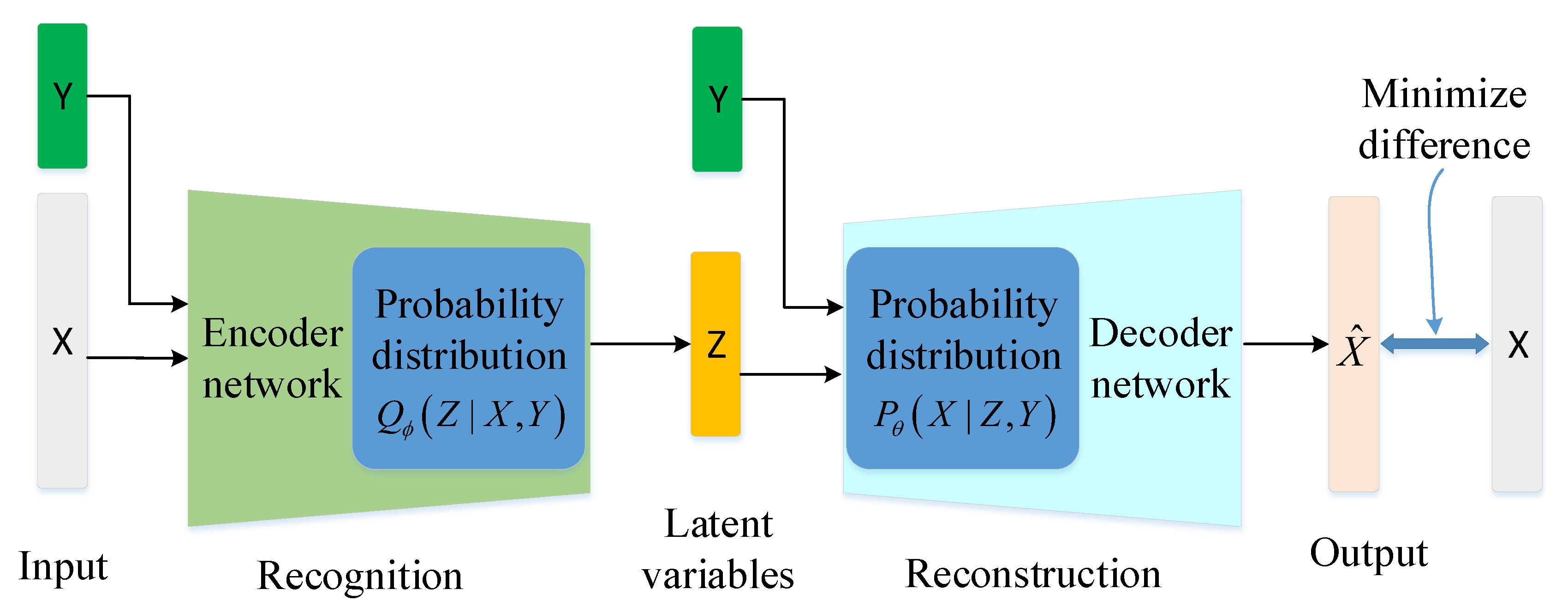
Sensors | Free Full-Text | Improving the Classification ...

Data Augmentation for Deep Candlestick Learner | DeepAI
Post a Comment for "40 variational autoencoder for deep learning of images labels and captions"